Lora vs QLoRA
2025.08.31 Back to posts
Lora vs QLoRA
訓練語言模型(LLM,SLM)需要考慮 GPU 的記憶體空間(memory size)
| GPU 記憶體 | 訓練方式 |
|---|---|
| 足夠 | full tuning |
| 不足 | finetuning (LoRA/QLoRA) |
Full Tuning
全參數微調需要大量 GPU 記憶體,因為需要載入完整模型權重、梯度和優化器狀態。
使用方式:
- 載入預訓練模型的完整權重
- 對所有參數進行反向傳播和更新
- 儲存整個模型的更新後權重
- 推論時直接使用完整更新後的模型
Library:
LoRA (Low-Rank Adaptation)
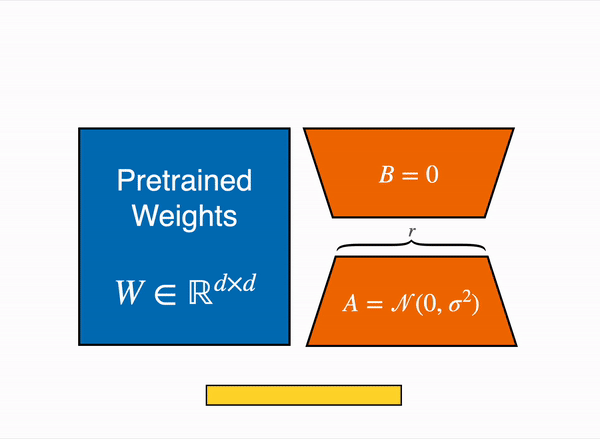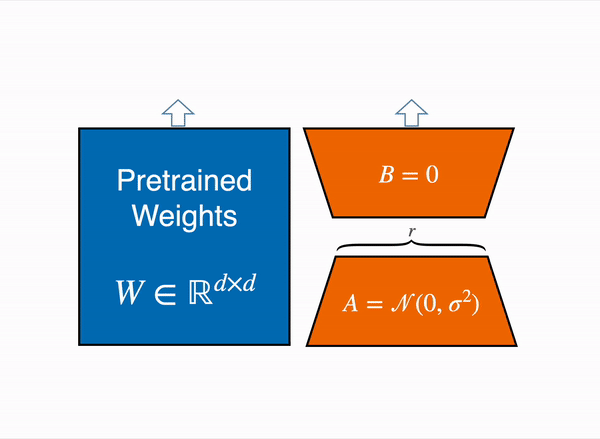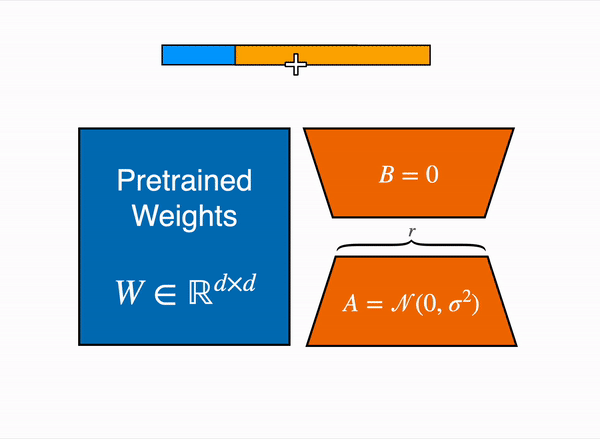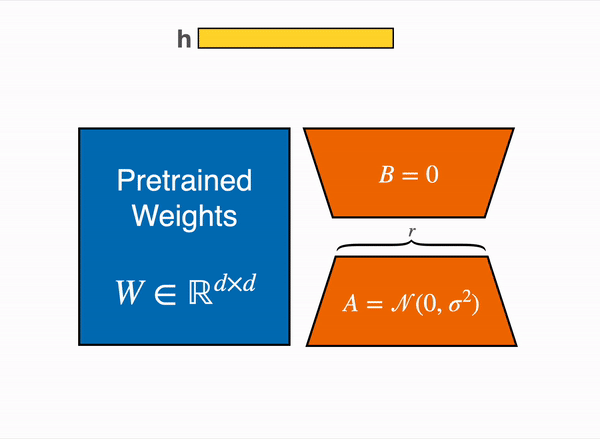 不去訓練原本模型的權重,而是訓練旁邊的小型低秩矩陣,訓練完成時將兩模型合併使用。
不去訓練原本模型的權重,而是訓練旁邊的小型低秩矩陣,訓練完成時將兩模型合併使用。
使用方式:
- 凍結原始預訓練模型的權重
- 為關鍵層(通常是注意力層)添加低秩分解矩陣 (A×B)
- 只訓練這些低秩矩陣,原模型參數保持不變
- 訓練完成後,可以選擇:
- 合併 LoRA 權重與原始模型(W + ΔW = W + A×B)
- 或保持分離,在推論時動態結合
Library:
量化(Quantization)
模型由高精度(BF16,FP16)轉為低精度(load 4 bit or 8 bit) 目的:
- 降低記憶體需求
- 加快推理
量化精度
| 量化位寬 | 描述 | 記憶體節省 |
|---|---|---|
| FP32 (32-bit) | 標準浮點精度 | 基準線 |
| FP16 (16-bit) | 半精度浮點 | 減少 50% |
| INT8 (8-bit) | 8位整數 | 減少 75% |
| INT4 (4-bit) | 4位整數 | 減少 87.5% |
Library:
QLoRA (Quantized LoRA)
將原本的大模型以 4-bit 量化方式載入以減少記憶體的消耗,使得同樣的記憶體可以跑更大的模型。
使用方式:
- 將預訓練模型量化至 4-bit 精度載入 GPU
- 使用 Double Quantization 進一步減少記憶體使用
- 添加 LoRA 適配器層進行訓練
- 使用 Paged Attention 管理記憶體
- 訓練時僅更新 LoRA 參數
- 訓練完成後得到 LoRA 適配器權重
- 推論時可以:
- 與原始全精度模型合併使用
- 或與量化模型一起使用
Library:
這兩種方法都能顯著減少微調所需的計算資源,使在消費級 GPU 上也能微調大型語言模型。