MINIRAG: Towards Extremely Simple Retrieval-Augmented Generation
2025.05.01 Back to posts
MINIRAG: Towards Extremely Simple Retrieval-Augmented Generation
Authors:
- Tianyu Fan → University of Hong Kong
- Jingyuan Wang → University of Hong Kong
- Xubin Ren → University of Hong Kong
- Chao Huang → University of Hong Kong
🎯 Abstract
Motivation
- Need for lightweight and efficient RAG solutions (SLM→LLM)
- Current challenges with Small Language Models (SLMs):
- Limited semantic understanding
- Text processing limitations
- Difficult application with performance degradation
Solution
- Introduction of semantic-aware heterogeneous graph
- Development of lightweight topology-enhanced retrieval approach
Results
- Performance comparable to LLM-based solutions
- 25% reduction in storage space
📚 Introduction
Current RAG Challenges
- LLM Dependencies:
- High computational costs
- Resource-intensive
- Difficult implementation on lightweight devices
SLM Characteristics
- Advantages:
- High computational efficiency
- Low deployment costs
- Disadvantages:
- Limited semantic understanding
- Poor RAG performance
- Implementation difficulties
MINIRAG Features
- Semantic understanding through pattern matching and localized text processing
- Utilization of structural information
- Step-by-step problem decomposition
Technical Innovations
- Semantic-aware heterogeneous graph indexing mechanism
- Lightweight topology-enhanced retrieval approach
Performance Highlights
- 1.3-2.5× higher effectiveness
- 25% storage space reduction
- Only 0.8~20% performance reduction from LLM to SLM
🔬 Framework
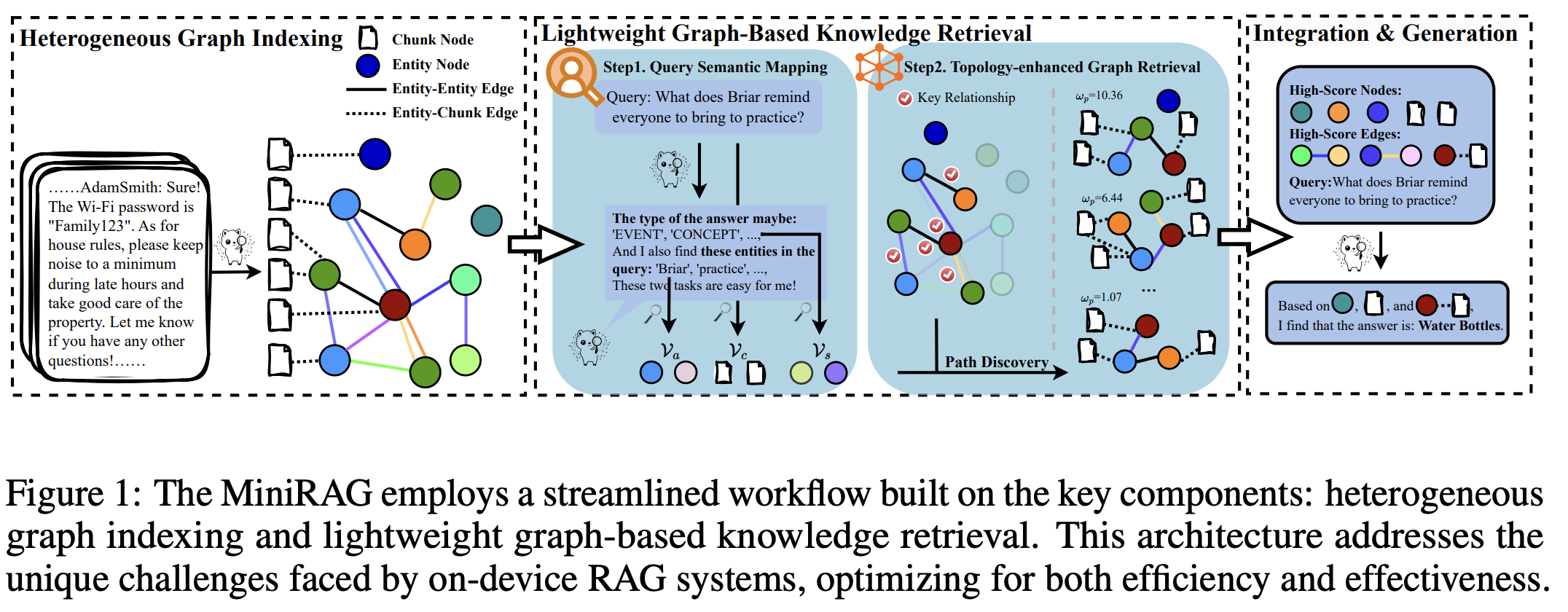
Heterogeneous Graph Indexing
Objectives
- Address SLM’s limitations in:
- Relationship extraction
- Contextual understanding

Design Goals
- Effective extraction of key relationships
- Establishment of entity($V_e$) & chunk($V_c$) relationships
- Minimization of information loss
Structure
- Dual node system:
- $\varepsilon_\alpha$: entity-entity relations
- $\varepsilon_\beta$: entity-chunk relations
- $d_{e_\beta}$: edge weight
Mathematical representation: $$D = G = ({V_c,V_e}, {\varepsilon_\alpha,(e_\beta, d_{e_\beta}) \in \varepsilon_\beta})$$
Lightweight Graph-based Knowledge Retrieval
Query Semantic Mapping
Process flow: $$Input Query \rightarrow \hat{V_s}(starting points) \rightarrow \hat{V_a}(potential answers) \rightarrow \hat{V_c}(supporting evidence)$$
Topology-Enhanced Graph Retrieval
Path scoring formula: $$ ωp(p | v_q) = ωv(\hat{v_s} | v_q) \cdot (1 + \sum_{v∈(p∧\hat{V_a})} count(v, p) + \sum_{e∈(p∧\hat{E_α})} ωe(e)) $$
Edge weight calculation: $$ ωe(e) = \sum_{\hat{v_s}∈\hat{V_s}} count(\hat{v_s}, \hat{G_{e,k}}) + \sum_{\hat{v_a}∈\hat{V_a}} count(\hat{v_a}, \hat{G_{e,k}}) $$
📊 Evaluation
Experimental Setup
- Datasets:
- Synthetic personal communication data (GPT4-generated)
- Short documents from multi-hop RAG dataset
- Implementation Details:
- Chunk size: 1200
- Overlap: 100
- Nano vector base for lightweight deployment
- top-k = 5
- Maximum tokens: 6000
Results
- Superior performance compared to traditional RAG approaches
- Significant storage space reduction
- Maintained effectiveness with SLM implementation
🏁 Conclusion
- Successfully addresses RAG deployment limitations on SLMs
- Enables private, efficient, and effective on-device RAG implementation
- Demonstrates potential for widespread application in resource-constrained environments
📖 References
Comments:
- This is a shared paper review, not written by me.